Insertion of generated code into java programs is the main subject of this paper. Such an automatic source code transformation is commonly referred to as code instrumentation. In this paper it covers anything beyond code generation, to get a java program checking its own constraints. For an idea, where code generation ends and instrumentation starts, see section ![[*]](crossref.png) .
.
This is followed by an analysis of requirements for the code instrumentation and resulting design decisions in section . Section describes the solution in detail.
Finally sections and discuss the more fundamental issue, when and how often invariants have to be checked.
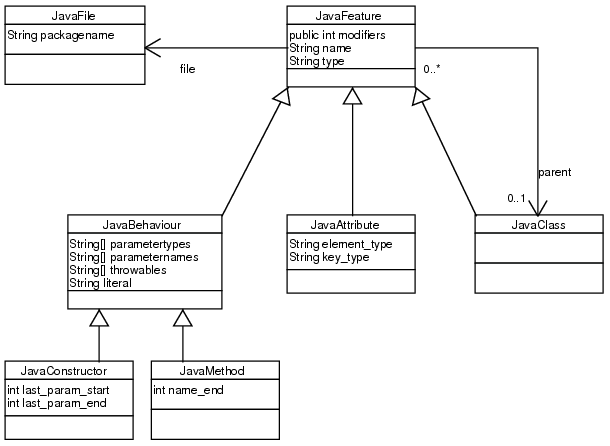
The java code generator developed in [FF00] produces a set of code fragments3.1. These code fragments have the following properties:
| Property | |
| Constrained type | The class this constraint applies to. |
| Kind | Specifies, whether this fragment is an invariant, a pre- or a postcondition or a transfer or preparation fragment for a postcondition. |
| Constrained operation | The operation, this constraint applies to (not valid for invariants). |
| Code | Contains the actual java code to be executed. |
| Result variable | Specifies the name of the boolean variable, which contains the result of the OCL expression after code execution. |
For each postcondition containing a @pre expression there are two additional code fragments called preparation and transfer. See below.
The meaning of preparation and transfer fragments is explained on a dramatically simplified example.
Suppose a post condition for operation employ(), that leaves the attribute age unchanged:
| Kind | Code |
| Transfer | int node1; |
| Preparation | node1=this.age; |
| Post Condition | int node2=this.age; |
| boolean result=(node1==node2); |
Typically these fragments would be inserted as follows:
.
This section analyzes the requirements for the code instrumentation and derives some fundamental design decisions.
The most important feature is the reversability of code instrumentation. It must be possible to
.It should be possible to embed constraints in the javadoc comments. The placement of embedded constraints implicates (and replaces) the context of the constraint. See the example below.
Invariants may also be placed on an attribute or method of their context class. This is for convenience, since most invariants are clearly related to one specific attribute or method.
The instrumented code must check, that container attributes comply to the @element-type and @key-type javadoc tags. For collections the @element-type tag specifies the type of the objects allowed in the collection. For maps @element-type specifies the type of values, while @key-type defines the type of key objects. A detailed description is provided in section .
Note, that this feature may be used standalone, without OCL expressions at all. Then it provides a runtime check for typed collections.
The main task of code instrumentation is to have some code executed immediately before and after all methods (and after all constructors too). This section describes, how this is done by the tool developed with this paper.
At first, section intoduces a simple approach, and why this would not work. Sections and explain the approach followed in this work. A somewhat tricky caveat and how it is solved is worked out in . Section shows, how it is managed to undo all modifications of the instrumentation. The java parser used to do all this is outlined in .
Sections , and compare this solution to three other tools approaching a similar task quite differently. This is summarized in .
A straight-forward solution would insert the code directly into the method. Consider the following method.
.
Additionally, item 4 requires much of the semantic analysis performed by a java compiler. This makes the simple approach very hard to implement.
Jass ([JASS]) and iContract ([RK98]) use this simple approach and encounter all the problems mentioned above. For a detailed comparison see sections and .
Method wrappers solve all these problems in a nifty but simple way. This is introduced in the following section.
Some code tells more than thousand words, so an example is used to explain. Consider the following method.
how easy it is.
This kind of method wrapping still has a problem, which has been called the ``wrapper loop'' in this paper. Section shows how this is solved.
Another transformation is used for constructors, since they cannot be renamed. Suppose an example constructor.
Wrapping methods as described in section causes a problem for a special situation. This sections describes this situation and provides a solution.
The critical situation is shown in the figure below:
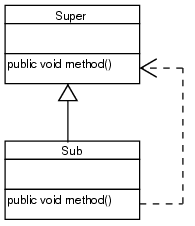
The dotted arrow represents a method call: Sub.method() contains a statement super.method(); somewhere.
The code instrumentation changes the structure as shown below:
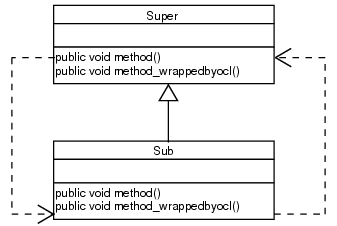
The arrows show the problem: there's an infinite loop of method calls. In detail the following happens:
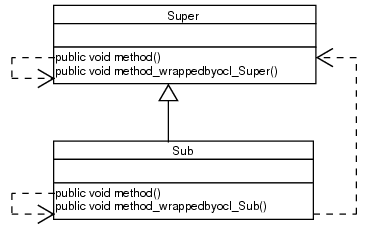
Wrapped methods get the class name appended. Thus, a wrapper method can call the wrapped method of its own class.
Reversable modification means, that the instrumented code can be cleaned from any modifications without leaving any traces. This section explains, how this requirement is met.
The user code is modified in two different ways only:
Removing generated class features relies on the fact, that all generated features get a special tag as shown below.
Previous sections stated, that a very simple parser is sufficient for implementing wrapper methods. This is proven in this section by giving an overview of the parser's design. In fact, it is as simple as a parser used for syntax highlighting and class browsers in a java IDE.
First, the parser is actually a manipulator. The java file is simultaneously read, parsed, modified on-the-fly and written to an output file. For a class diagram of the parse tree produced see figure .
The parser analyses things which are relevant for the parse tree only. Particularly method bodies and attribute initializers are ignored. These skipped parts may not even compile. As long as the parenthesis balance is held, the java parser will process them correctly.
Jass ([JASS]) is a precompiler for checking assertions in java programs. It translates jass files into java. Jass files are valid java source code with assertions specified in comments. The generated java file contains additional code checking these assertions. Thus, Jass performs something similar to the code instrumentation presented in the sections above.
However, Jass directly inserts generated code into user code as described in section . Thus the problems found there should occur in Jass too:
. Thus, Jass must be run before compilation whenever the source code has changed. Additionally, the source code repository must hold jass files instead of java, which causes administration effort for existing projects.
Jass cannot use wrapper methods, since this would not allow loop invariants and check statements to be implemented. But without these features as in OCL, method wrappers are much better than direct insertion of code.
iContract ([RK98]) is a precompiler for checking OCL constraints in java programs. It extracts constraints from javadoc comments and produces modified java source files checking these constraints. This is exactly the functionality, which the tool presented in this paper tries to provide.
Just like Jass it uses direct insertion of generated code into user code. Once again the problems found in section are reviewed.
.This paper is focused on source code instrumentation. Another approach is to modify java byte code. This section discusses, whether it's possible and useful, to apply the concept of method wrappers to byte code instrumentation.
For the third time the problems found in section are reviewed.
, since the JVM Specification [LY97] wasn't that clear about it.In contrary to the approach presented in this paper, byte code instrumentation has to be redone after every compilation of the source code. This may be done on the fly, when loading the classes into the JVM. For instance jContractor [KHB98] uses a class loader to instrument java code. This may cause problems, if the user code registers a class loader of it's own. This is solved by Handshake [DH98], which uses a proxy system library to intercept the JVM when opening class files. Thus, Handshake buys total transparency to the JVM with platform dependency.
Wrapping methods seems to be the best choice when instrumenting source code for checking constraints. Several problems encountered with the simple approach of direct insertion are solved.
Method wrappers cannot be used, if implementation constraints (assertions, loop invariants) are to be checked. Since OCL does not support implementation constraints, this does not affect the scope of this paper.
Method wrappers are not useful for instrumentation on byte code level. The biggest advantage of source instrumentation (if it is reversible) is, that it doesn't need to be redone on each recompilation.
This section discusses the issue, when an constraint is required to be fulfilled. This is trivially for pre/post conditions, but for invariants it's not so easy.
[WK99] section 5.4.2 suggests to check invariants immediately after an object has changed3.4. This is not workable, even if runtime efficiency is ignored. Modifications on the model often produce intermediate states, which are not consistent according to the constraints.
When using databases the answer is simple: invariants must be valid outside of transactions. Since the java system does not provide transactions there are several strategies offered for various user requirements.
Invariants may be required to be fulfilled on:
There won't be a single solution for this problem. Many applications will require their own individual scope of invariants. The scope may even differ between several classes of invariants.
The current implementation supports scopes needed during the ongoing diploma thesis only. Up to now, all invariants share the same scope. Also, tagged methods are not yet supported.
The previous section discussed, when we have to make sure, that all invariants are fulfilled. But even then it's not absolutely necessary to evaluate all invariants. The implementation developed along with this paper checks only those invariants, whose result may possibly have changed by recent changes of the model.
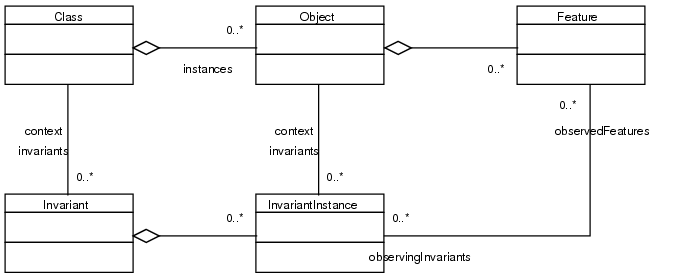
Caching is realized with an observer design. Each invariant determines all object attributes it depends on and registers to these attributes as observer. Figure shows the meta model of the principal design.
The classes in the UML chart have the following meaning:
| Class | Example | |
| Class | An arbitrary class of | class Person |
| the user model | ||
| Invariant | An invariant in the | context Person |
| context of a class | inv: age>=0 | |
| Object | An instance of a class | Person Joe |
| Invariant- | An invariant in the | Has Joe |
| Instance | context of an object. | a positive age? |
| Feature | A feature (attribute or | Joe's age |
| query method) of an object. |
For now, lets think of features as attributes only. How to deal with query methods is explained below.
The cycle of checking invariants contains two stages.
how changed attributes are detected..
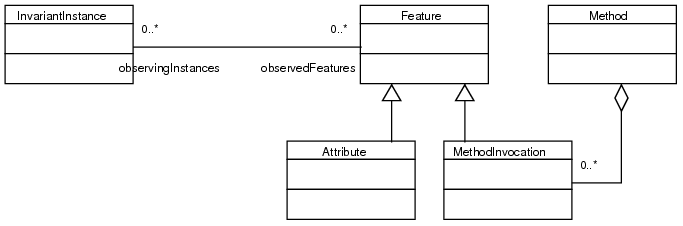
The point is, that not methods but method invocations are features observed by invariants. A method invocation is a method together with a parameter sequence suitable to invoke this method.
Up to now, the implementation observes attributes only.
Not all of these classes exist explicitly in the implementation. Class and Object are provided by the user model already. Invariant exists only as an additional method checkOclInvariant_<name> of its context class. InvariantInstance is an explicit class3.6 of the instrumentation runtime library. Finally Feature is provided by the user model, but cannot be referred to as a single java object. (java.lang.reflect.Field is a field of a class, not of an object.) Whenever a feature has to be referred to, it is represented by it's observer collection object, which is sufficient for the needs of this implementation.
Changes of object features are detected with polling. For each feature a backup attribute is added to the class.
For collections the backup stores a hashcode of the collection to avoid the overhead of maintaining a complete backup collection. Since comparison to backups is done very often, hashcode computation is required to be lightweight. The following section discusses this in detail.
Detecting changes of attributes is essential for caching of invariants as described above. For atomic attributes this is trivial: age!=age_backup does it all. For collection attributes it's not that easy. The backup of a collection shouldn't be a collection as well, since this would consume large amounts of memory. Also, comparison between two collection isn't that fast.
Thus, the backup for collection attributes stores a single integer value only. This value is computed from the collection. When the collection changes, also the value is expected to change. Such a value is commonly referred to as hash value.
However, these hash values are not required to be uniformly distributed. Also, the hash value is required to be constant for unmodified collections only, not generally for equal collections. This means: if an element is added to the collection and removed immediately afterwards, the collection is not required to have the same hash code as before. This relaxion of requirements will be used below. It has to be admitted, that the term ``hash code'' is used here mainly for historical reasons.
A first try to implement the hash functions follows the implementation of hashCode methods in the Java Collection API. These methods cannot be used directly, since they call method hashCode for each of their elements. This is not desired, since change detection covers object identity, not object value. To achieve the intended behavior, collection hash functions had to be rewritten with calls to System.identityHashCode. This has been implemented in class HashExact3.7.
These hash functions are good at detecting changes. However, they are too slow. Each invocation involves an iteration over the whole collection. For object populations of a few hundert instances with many relations between them, this virtually causes the system to stop.
A quick but incomplete fix is achieved with the hash functions in HashSize. They simply return the size of the collection. This is very quick of course. But it does not detect changes which don't affect the collections size.
Finally, HashModCount performs a hash function which is a) nearly as fast as HashSize, but b) performs change detection even better than HashExact. It uses the fact, that standard collections already provide a change detection mechanism for implementing fail-fast iterators. Each collection maintains a modification counter, which is incremented whenever the collection is modified. Iterators create a copy of this counter on creation, and check this copy on every access. Unfortunately, the counter isn't publicly available. Thus, HashModCount has to access the private counter attribute via reflection. This is highly dependent on the internal details of collection classes. The implementation has been tested successfully on JDK 1.2.2. With other versions better do not expect it to work.
There is a work-around for this. The collection backup could be an iterator instead of an integer. To detect a modification, just access the iterator and wait for a ConcurrentModificationException. This has not been implemented yet, since it imposes several problems. Method hasNext() does not check for modifications. Thus, method next() has to be invoked. But this may also fail due to NoSuchElementException if there are no elements left. Thus, the iterator used for backup would have to be recreated, whenever there is no element left. Empty collections would require a special treatment.
Using the fail-fast mechanism obviously does not work for arrays. However, a fall back to HashExact or HashSize is easily provided. This could even be decided dynamicely depending on the size of the arrays.
The table below summarizes the different detection mechanisms:
| Exact | Size | ModCount | Iterator | |
| Modification | nearly perfect | insertion/ | perfect | perfect |
| Detection | deletion only | |||
| Runtime | linear | constant/ | constant/ | constant/ |
| Complexity | very low | low | intermediate | |
| Implemention | yes | yes | yes | - |
| Works with | ||||
| Arrays | yes | yes | fall back | fall back |
| to other | to other | |||
| Collections without | yes | yes | runtime | silent |
| Fail-Fast Iterators | error | failure | ||
| Non-JDK | yes | yes | runtime | yes |
| Collections with | error | |||
| Fail-Fast Iterators | ||||
| JDK Standard | yes | yes | yes | yes |
| Collections |
Finally there is the question, which to choose. Probably one should start with Exact (the default). If this works, everything is fine. If the application slows down more, than one is willing to accept, try ModCount (invoked with option -modcount-hash). If this works, it's fine. Otherwise it will fail-fast throwing a RuntimeException. Then one may try Size (-simple-hash). Hopefully it doesn't miss too many modifications.
If this is not acceptable, one may implement the Iterator method. It is important, that all collections used in the application provide fail-fast iterators (JDK standard collections do). Otherwise modifications may be missed silently.