This chapter describes the problem I solved for verification of XML-QL. It describes the problem in detail, so the reader can understand the difficulties I found during implementation.
The type information component is a part of the OCL compiler developed by Frank Finger. The compiler does some type checking on OCL constraints. Therefore it needs information from the model. The compiler supplies a java interface, which the type information component has to implement. Up to this point, there was only an implementation featuring a hard-wired example model. The component developed here enables the OCL compiler to process OCL constraints on arbitrary models given in XMI.
This is the interface, as given by the OCL compiler. For further details see [FF] package tudresden.ocl.check.types.
Methods navigateQualified, navigateParameterized and getClassifier never return null. Instead they throw an exception, if the queried feature/classifier is not available.
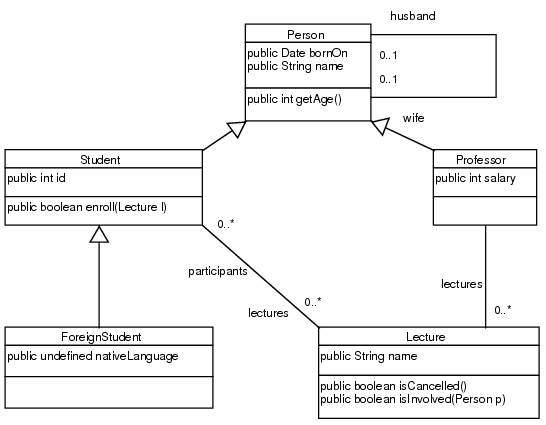
This section explains the interface introduced above in detail using an example model. For the example see figure 3.1.
At first the model has to be created. Using the XMI parser this is achieved by
The model is used to get objects representing classes of the model. These objects are subject to further queries.
Generalizations beetween classes of the given model are checked with conformsTo.
At first some obvious examples.
Association ends featuring multiplicities of more than one result in collections.
The model must find all features of a class. This includes features inherited from super classes.
The model must find operations, even if parameter types are not exactly the same as in the operation definition. For demonstration, the last statement of the paragraph above is slightly modified.
Associations in UML are entities of their own. The type information component dissolves associations into a set of structural features for each class of the association. This section describes the algorithm used to dissolve an association formally. The algorithm closely follows [OCL].
In a first step, we don't care about association classes.
| isMultiple | isOrdered | Type |
| false | - | class |
| true | false | set of class |
| true | true | sequence of class |
Bags are never generated by the type information model.
For each pair (A,B) of association ends with ![]() the structural feature representing B is added to the class connected to association end A.
the structural feature representing B is added to the class connected to association end A.
The second step makes the association class reachable from the classes connected to association ends.
![]()
To each class connected to an association end a structural feature is added. The name of the feature is the name of the association class (which is the name of the association) starting with a lower-case letter. The type of the feature is determined by the following table.
| othersAreMultiple | Type |
| false | association class |
| true | set of association class |
The third step makes the association ends reachable from the association class.
For each association end a structural feature is added to the association class. The name of the feature is the name of the association end. The type of the feature is the class connected to the association end.
Note that when navigating from the association class to association ends the model never returns collections, regardless of the association ends multiplicity.
An attribute ambiguity occurs, if a classifier has more than one feature of the same name. Consider the following example.

SomeClass has two features called ``anotherClass'':
The same applies to ``AnotherClass''. It has two features ``anotherClass''. Both are implicit rolenames of the reflexive association. Again, this causes both features ``anotherClass'' to be unavailable for OCL.
[OCL] does not specify, whether a subclass may override an ambiguous feature, thus making the feature available again. For example, suppose a subclass ``SubSomeClass'' of ``SomeClass'' having an attribute ``anotherClass''. One could argue about, whether this feature is available for OCL or not. Current implementation of the type information component makes the feature available again, however this could be changed easily.
Operation matching is a problem to be solved by any compiler. There is a operation call and given set of operations with the same name. The question is, which operation actually gets called.
Suppose a generalizationship of two classes
But its not as easy, as it looks. To explain, the model above is extended.
The current implementation of the type information component cannot handle either of the queries. Instead, it will generate an exception due to ambiguous operations. More formally:
This section explains the design of the component I developed. It consists of two parts:
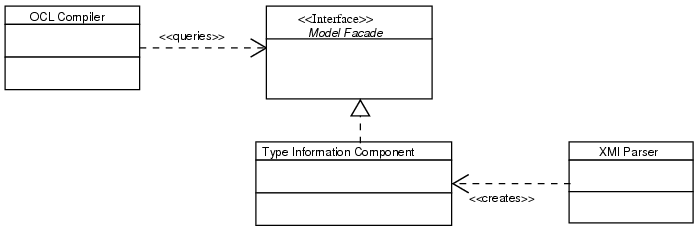
See the figure 3.3 for an static UML structure of the type information component.
At the right there is the interface provided by the OCL compiler. This has been discussed in detail in section 3.1.1.
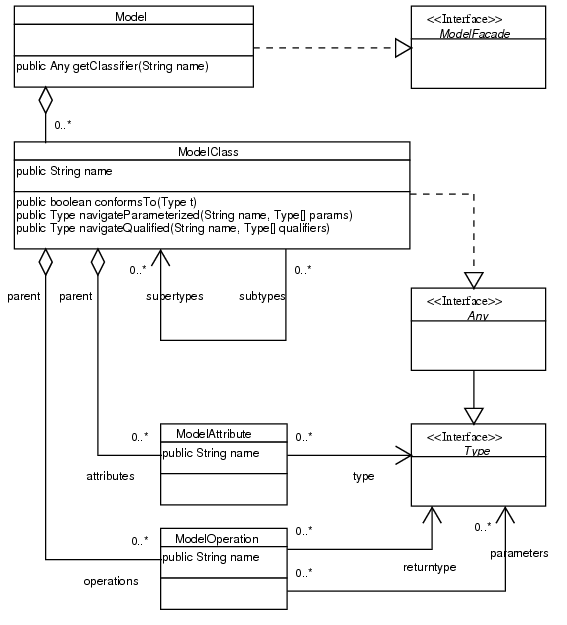
The classes at the left store the type information and implement the interface ModelFacade to answer the queries from the compiler.
It is not possible to store associations explicitly. Instead, associations are dissolved into a set of structural features (attributes) according to section 3.1.3. Dissolving associations is implemented by the method ModelAssociation.dissolve(Model).
After creating the model structure, there is a final step of flattening the model. This means, that for each class
The parser is essentially a collection of methods, creating the Type Information Component. So there is not much to be designed.
The XMI parser uses XML4J to parse the XML file. XML4J is provided by IBM for free. XML4J implements the DOM model provided by the W3C. This standardizes the way, a java application accesses a XML file. Thus, the XMI parser does not depend on an interface proprietary to IBM.
A XMI adapter adapts the parser to different versions of XMI. For the XMI Parser there are two different versions to be distinguished. Both differ in naming of tags and attributes. See the table for details.
| Version | OMG | IBM |
| Rational Rose XMI Plugin | Argo/UML 0.7 | |
| attribute name | xmi.id | XMI.id |
| attribute name | xmi.value | XMI.value |
| attribute name | xmi.idref | target |
| element name | Foundation.Core.Class | Class |
| element name | Foundation.Core.ModelElement.name | name |
| element name | Foundation.Core.Generalization | Generalization |
| element name | Foundation.Core.Generalization.subtype | subtype |
| ... and so on. | ||
Originally, XMI has been developed by IBM. The OMG adopted XMI as a standard representation of UML. Unfortunately, the OMG has prefixed all element names with their packages of the UML specification. This makes XMI documents less readable by humans, more tedious to parse and noticeably larger in size.
There are further differences of the XMI generated by the tools mentioned above. One example is illustrated here.
This is an extract of the XMI structure generated by Argo/UML:
In other words: Argo puts each <Class> element into its own <ownedElement> element, while Rose put all <Class> elements into a single <ownedElement> element.
This problem is solved by defensive programming. The parser simply accepts multiple <ownedElement> elements, each having multiple <Class> elements nested inside.
The table below list all similar cases of different nesting, the author found during implementation. Probably, this list is not complete.
| Class | Rolename | Associated Classes |
| Model | ownedElement | Class, Association, Generalization |
| Association | connection | AssociationEnd |
| Class | feature | Attribute, Operation |
| Operation | parameter | Parameter |
This section discusses selected issues of the implementation.
The type information component with the XMI parser requires the Java Collections API. Since the OCL compiler does depend on Java Collections too, this is no problem.
Additionally XML4J is needed. It is available at the IBM website. Development and testing was done using version 2.0.15.
The parser was tested with Argo/UML 0.7 and Rational Rose 98sp1 with the Unisys XMI Plugin.
[OCL] specifies, that OCL expressions may not use operations with side effects. XMI makes this information available by the isQuery element. However, neither Rose or Argo do support setting the isQuery information by the user. Instead, it is set to false for all operations. Therefore the XMI parser ignores it.
This section describes the test cases performed on the type information subsystem. There are several tests, some replacing some of the components with test drivers. For understanding, please refer to the type checking subsystem architecture figure 3.2 on page ![[*]](crossref.png) .
.
The following tests use a model featuring the ``Royalties and Loyalties'' example model. The OCL compiler processes some OCL expressions written by Frank Finger for the example model.
In this test case the XMI Parser component replaced by a test driver. The test driver directly creates the example model.
This test case runs the entire system. The XMI Parser creates the example model twice from two XMI documents. The first one was created using Argo/UML 0.7. The second document has been exported from Rational Rose using the Unisys Plugin.
The example model of the tests above does not cover the more subtle problems of the type information component. The model lacks
The test case replaces the OCL compiler (see figure 3.2 again) by a test driver querying the Model Facade. This makes more precise testing possible. For failing queries it is additionally checked, whether they fail for the intended reason. Possible reasons for failure are attribute ambiguity, method ambiguity and the simple absence of the feature queried.
The following queries throw an OclTypeException due to attribute ambiguities:
However,
This query throws an OclTypeException due to method ambiguity.
two.navigateParameterized("operation", { gamma }) == gamma